AIL vs PCIL
Comparison between the representation space of AIL method and our method
Since the AIL methods use a binary classification objective to distinguish expert and non-expert transitions, the representation space is only required to separate two classes in two disjoint subspaces. So the embedding space is not required to be semantically meaningful enough.
We overcome this limitation by proposing PCIL. Our method enforces the compactness of the expert’s representation. This ensures that the learned representation can capture common, robust features of the expert’s transitions, which leads to a more meaningful representation space

(Left) the distance between 2 expert data points may be even longer than the distance between expert data point and sub-optimal non-expert data point. (Right) Our proposed PCIL.
Policy contrastive imitation learning
We first select an anchor state (the orange) from the expert trajectory. Then, we select a positive state sample (the red) from another expert trajectory and a negative state sample (the green) from the agent trajectory. We map these selected states to the representation space. Finally, we push the representation of the anchor state and the positive state together and pull the representation of negative samples away from the representation of the anchor state.
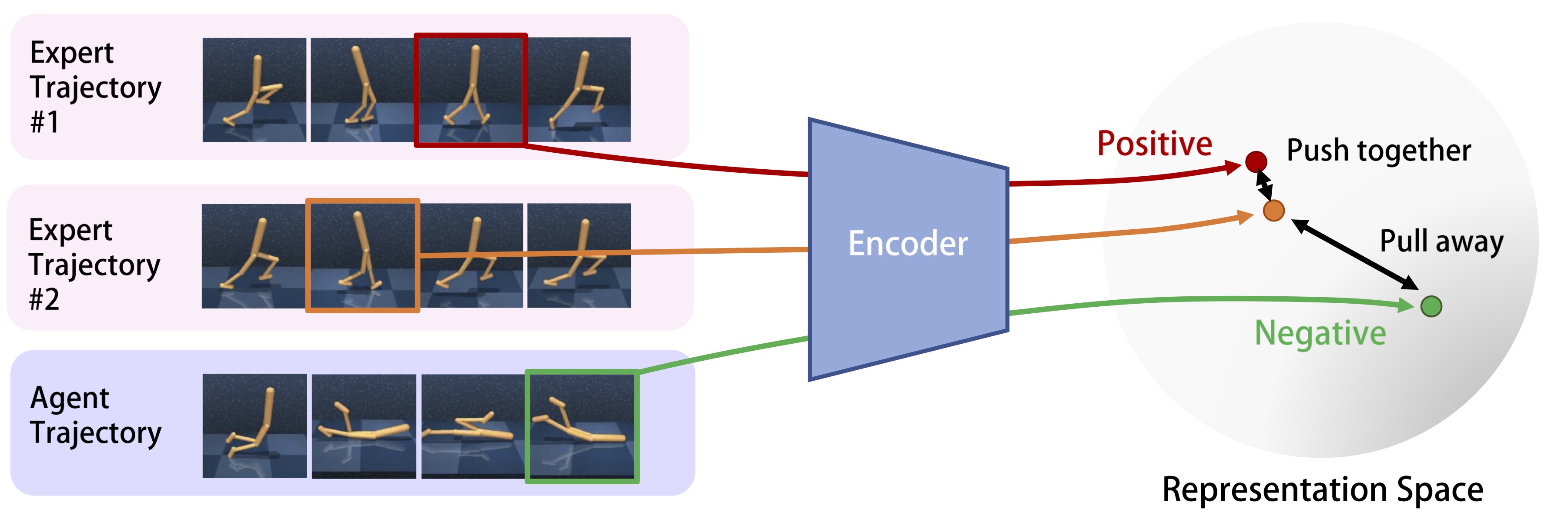
Illustration of our contrastive learning approach.
Results
We experiment with 10 MuJoCo tasks provided by DeepMind Control Suite. The selected tasks cover various difficulty levels, ranging from simple control problems, such as the single degree of freedom cart pole, to complex high-dimensional tasks, such as the quadruped run.
We find that PCIL is able to outperform the existing methods on all of these tasks. It achieves near-expert performance within our online sample budget in all considered tasks except Hopper Hop. In terms of sample efficiency, i.e., the number of environment interactions required to solve a task, PCIL shows significant improvements over prior methods on five tasks: Cheetah Run, Finger Spin, Hopper Hop, Hopper Stand, and Quadruped Run. For the remaining tasks,
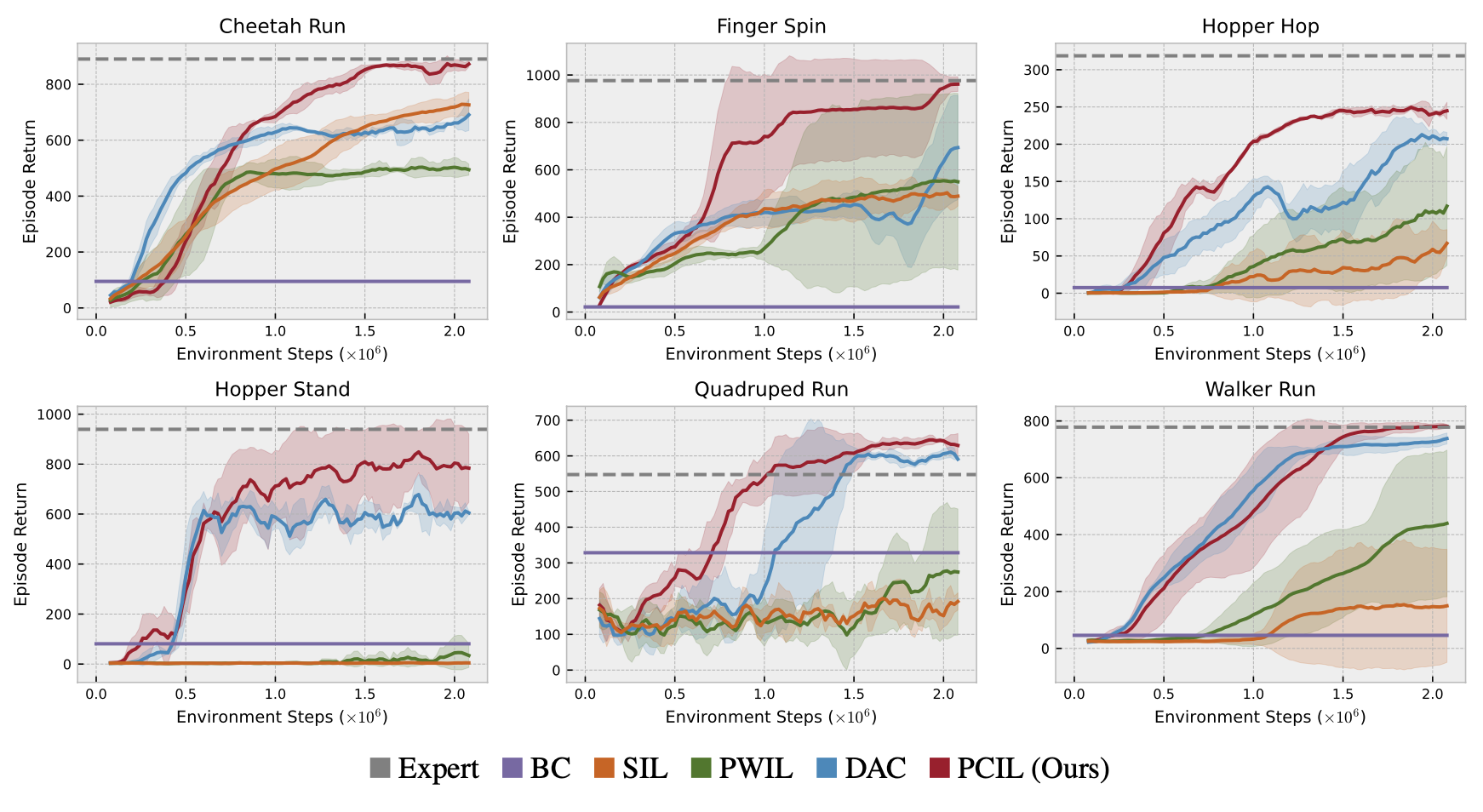
Comparisons of algorithms on 6 selected tasks.